Xuaner Zhang1, Qifeng Chen2,
Ren Ng1, Vladlen
Koltun3
1UC Berkeley, 2HKUST, 3Intel Labs
CVPR, 2019
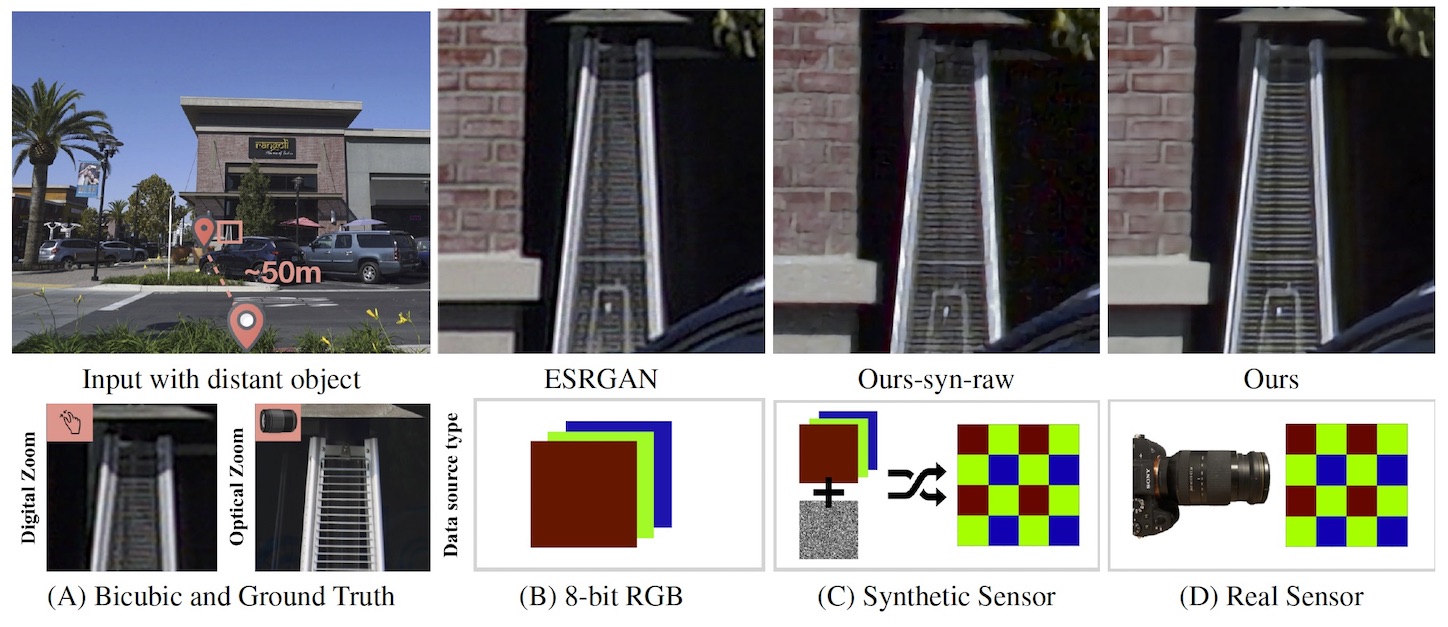
This paper shows that when applying machine learning to digital zoom for photography, it is beneficial to use real, RAW sensor data for training. Existing learning-based super-resolution methods do not use real sensor data, instead operating on RGB images. In practice, these approaches result in loss of detail and accuracy in their digitally zoomed output when zooming in on distant image regions. We also show that synthesizing sensor data by resampling high-resolution RGB images is an oversimplified approximation of real sensor data and noise, resulting in worse image quality. The key barrier to using real sensor data for training is that ground truth high-resolution imagery is missing. We show how to obtain the ground-truth data with optically zoomed images and contribute a dataset, SR-RAW, for real-world computational zoom. We use SR-RAW to train a deep network with a novel contextual bilateral loss (CoBi) that delivers critical robustness to mild misalignment in input-output image pairs. The trained network achieves state-of-the-art performance in 4X and 8X computational zoom.
Paper Supplementary Material Code
We have released our raw sensor dataset here. For each sequence, we capture 7 (few contain 6) images (RAW and JPG) taken by different focal lengths. One can train different levels of zoom models (e.g. 4X or 8X) using corresponding pairs within these sequences. A few example sequences are shown below for visualization (hover to see the entire sequence):








If you use our code or data, please cite:
@inproceedings{zhang2019zoom,
title={Zoom to Learn, Learn to Zoom},
author={Zhang, Xuaner and Chen, Qifeng and Ng, Ren and Koltun, Vladlen},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2019}
}